🗺️ Overview


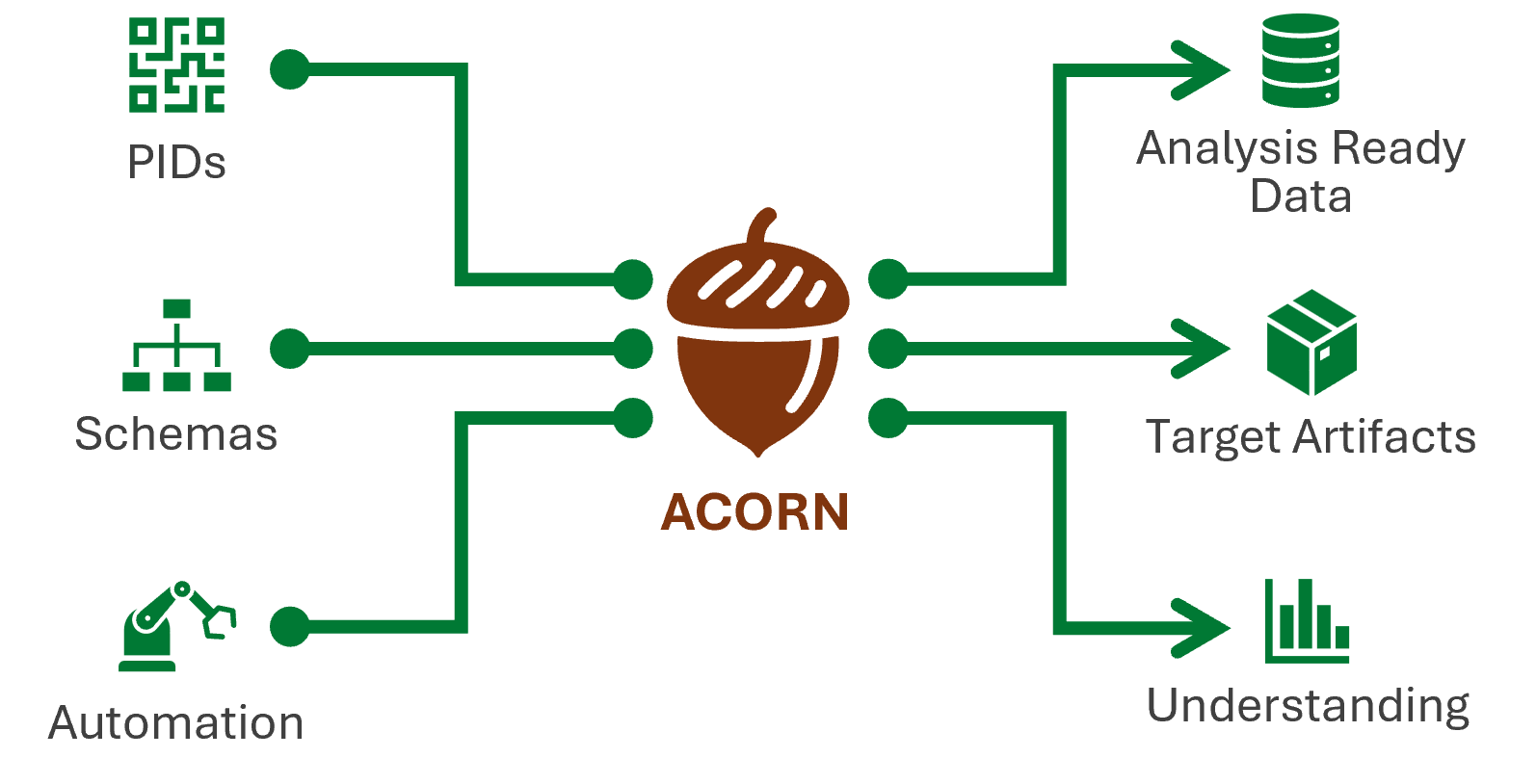
🌱 ACORN1 is a research assistant and metascience multi-tool that provides and operationalizes an ontology for research activity data (RAD). ACORN enables adding linked data context and transforming RAD into a knowledge graph that is amenable to automated reasoning and artifact generation (e.g. PDFs, PPTX, etc.)
ACORN is a command line multi-tool that employs automated processes for informing and enforcing defined content schemas. With these content schemas, ACORN builds communication assets such as PDFs, presentation files, and web pages. It also lays the foundation for deep data insights about ORNL’s — and any institution’s — corpus of research. Built using the memory-safe Rust programming language, ACORN can be used on any Windows, Mac, or Linux machine
-
ACORN stands for “Accessible Content Optimization for Research Needs ↩
🤔 So what? Big deal? Who cares?
Important
If you do science, you need ACORN.
🎯 What is ACORN trying to solve?
Accessible Content Optimization for Research Needs, ACORN, allows science achievers and communicators to create analysis-ready research activity data. ACORN’s associated schemas standardize how research is codified and communicated to capture the entire research architecture, including what research is being done, how it’s done, and how it all relates.
Built with memory-safe Rust, ACORN is a portable solution that uses statically typed and dynamically validated data structures. Schemas include unique identifiers1 to support open science principles and practices.
ACORN can help inform researchers, sponsors, and partners, as well as train machines on existing research projects. It can also identify where gaps in a body of research exist.
🆕 How is it novel?
ACORN focuses on research at the project level. While there are other systems that track research projects tangentially — through people, publications, or organizations — there is no system we know of that employs projects as the primitive source of information. We believe codifying research activity data at the project level is the key to unlocking deep insights about an organization’s resources, funding, partnerships, and accomplishments. This network of linked data surpasses what may be already present but siloed in current search tools.
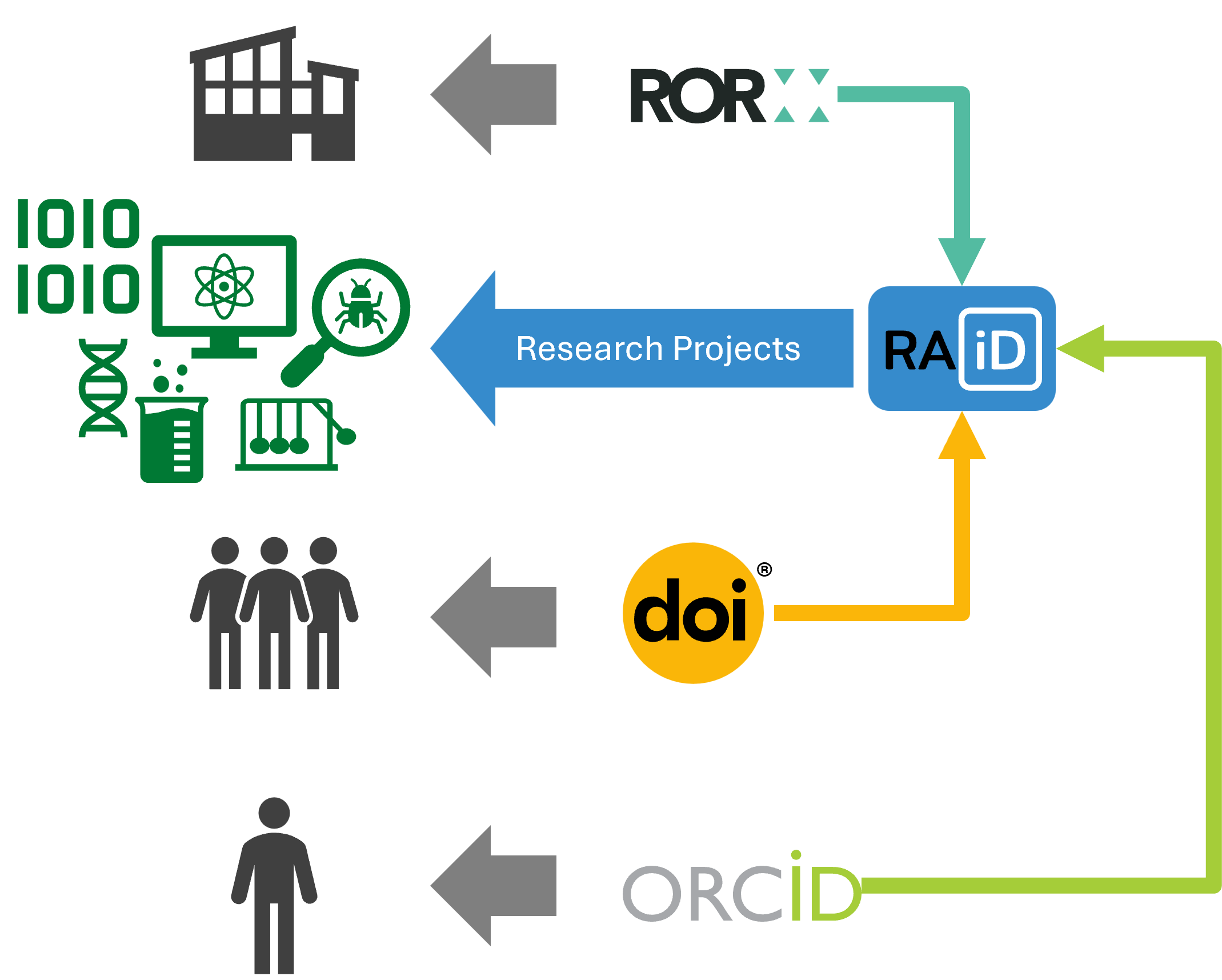
With existing tools, we can see
- publications2, but we don’t know about projects without journal publications or how projects relate,
- people3, but people move groups, change job roles, and leave organizations, and
- approvals and timelines, but these systems aren’t often designed to integrate with other PIDs or systems
- budgets, but budgets do not include the level of project details necessary to capture appropriate scientific understanding
ACORN does not replace or remove these systems. Each supports part of the puzzle. ACORN can help ensure they integrate and work together to provide users with valuable information from a central source of truth, no matter their entry point.
⚠️ What are the risks?
There are very few risks to ACORN. They would simply include anything that could preclude continued development of ACORN like lack of funding or human resources to support further development of the project. They also include any security risks inherent in projects at locations that host potentially sensitive data.
Even if it completely fails4, our “escalator” turns to stairs and remains useful. It is open source5, designed to be local and decentralized, and built on existing systems, with information stored in flat files so it will never be lost or unshareable.
Tip
Research activity data curated and controlled by ACORN and its associated schemas and processes will always hold value.
🎁 Why should I use ACORN?
You should use ACORN if you want your project to be part of the research conversation. We initially developed ACORN for researchers, to help capture and communicate their projects more effectively. ACORN helps cut down on administrative burden, allowing the PI or a project designee to submit descriptive metadata to a form and receive automatically generated fact sheets in PDF, web, or PowerPoint form. This form, kept as a JSON file in a designated repository6, becomes the single source of truth for information on each project. We continue to develop the metadata schema and talk with research groups to benefit organization processes.
-
ACORN provides CURIEs and will soon also work with research activity identifiers (RAiD) ↩
-
Realistically, the only mode of failure is complete lack of adoption… ↩
-
We call these repositories, “buckets” (see the page on buckets for details) ↩
🚀 Getting Started
Important
The most popular way to use ACORN is to not install it at all — simply leverage the power and promise of ACORN within a CI job (see this example
.gitlab-ci.yml)
Installation
Install with Scoop (Windows only)
-
Ensure you have Scoop installed.
-
Open your terminal and add the extras bucket to Scoop
scoop bucket add extras -
Run the following command to install ACORN
scoop install acorn -
After installation, you can verify the installation by running:
acorn help -
You can keep ACORN up to date with Scoop by running:
scoop update acorn
Install with Homebrew (Linux and MacOS)
-
Add the custom tap:
brew tap research-enablement/acorn https://github.com/research-enablement/homebrew-acorn -
Install ACORN:
brew install acorn-cli -
Verify installation:
acorn help -
Upgrade to the latest version:
brew update brew upgrade acorn-cli
Tip
You can use any tap URL for your organization. Keep the formula name as
acorn-cliso updates remain consistent.
Install with Cargo
-
Ensure you have Rust and Cargo installed. If not, you can install them using rustup.rs.
-
Open your terminal and run the following command to install ACORN
cargo install acorn-cli -
After installation, you can verify the installation by running:
acorn help
Run Inside a Container
-
Ensure you have Docker1 installed.
-
Pull the latest ACORN image with Docker1
docker pull savannah.ornl.gov/research-enablement/acorn/runner -
Run ACORN using Docker1
docker run --rm savannah.ornl.gov/research-enablement/acorn/runner help
Tip
You will probably need to mount a volume to use ACORN with your local files. For example:
docker run --rm -v $(pwd):/data savannah.ornl.gov/research-enablement/acorn/runner:latest check /data/project
Download pre-compiled binary
- Download the latest release from the ACORN GitLab Releases page
-
🪟 Windows
-
Open a PowerShell terminal, visit the releases page to find the latest version, and run:
irm -OutFile acorn.exe -Uri https://code.ornl.gov/api/v4/projects/16689/packages/generic/x86_64-pc-windows-gnu/v<version>/acorn.exe -
Test the downloaded executable:
.\acorn.exe help
-
-
🐧 Linux
-
Open a terminal, visit the releases page to find the latest version, and run:
curl -LO https://code.ornl.gov/api/v4/projects/16689/packages/generic/x86_64-unknown-linux-musl/v<version>/acorn -
Make the downloaded file executable:
chmod +x acorn -
Test the downloaded executable:
acorn help
-
-
🍎 MacOS
🚧 Under construction
-
Install from source
-
Clone the ACORN repository
git clone https://code.ornl.gov/research-enablement/acorn.git cd acorn -
Install
acorncommandcargo install --path ./acorn-cli -
After installation, you can verify the installation by running:
acorn help
-
These instructions will work with any OCI-compliant container runtime, such as Docker or Podman. ↩ ↩2 ↩3
Concepts
ACORN is built around a few core concepts to ensure its effectiveness. This section will introduce these concepts and explain their significance in the context of ACORN and science.
Motivation
For the last few decades, scientific progress has been driven largely by publishing papers in, ideally peer-reviewed, scientific journals. Publishing affords researchers recognition, career advancement, and funding opportunities. This model can be effective, but it has some serious limitations ACORN aims to address.
- Publish or perish1: Scientists and researchers often care more about publishing than about sharing knowledge. This is not without reason, as publications are a key metric for career advancement and funding. However, this can lead to a focus on quantity over quality and a reluctance to share negative results or data that does not support a hypothesis.
- Reproducibility crisis2: Many scientific results are difficult or impossible to reproduce, leading to questions about their validity. This is compounded by the fact that many publications do not provide access to the underlying data or code used in the research.
- No clear way to demonstrate science: Publications, people, and budgets do not tell the whole story. Science needs a cross-domain standard to collect and communicate the full context of scientific endeavors, including data, code, methods, and results.
ACORN addresses these issues by codifying the details of a research project and providing an automated framework for sharing and analyzing scientific knowledge. Predicated on the idea of applying “science all the way down”, ACORN applies rigorous scientific principles to the management and dissemination of scientific knowledge.
Research Enablement
ACORN is managed by the Research Enablement Initiative at Oak Ridge National Laboratory (ORNL). REI aims to improve the way scientific research is conducted, shared, and evaluated. It is a team of developers, communication experts, and information scientists passionate about open science, transparency, and improving the researcher experience.
REI provides:
- A cross-domain model of research activity data (RAD)
- A command-line application written in Rust -
acorn-cli - A Rust crate for working with RAD -
acorn-lib - A Python package for working with RAD -
acorn-py - A catalog of research activity data at ORNL - research.ornl.gov
🪣 Buckets
RAD lives in versioned folder collections called “buckets”. Each bucket contains a set of files and media assets that describe research activities. For multiple examples, see ORNL’s buckets.
Buckets can be combined via a flat-file3 configuration file using the ACORN CLI tool. This allows users to aggregate data from multiple sources and generate outputs such as reports based on the combined data.
Buckets are flexible and extensible - they do not require a cloud provider or expensive infrastructure to use. They can be stored in any version-controlled repository, such as GitLab, GitHub, or even a local file system.
Buckets are designed to enable federation and scaling while maintaining low-level control over permissions and access. This allows organizations to share data across teams and departments while maintaining control over who can access and modify the data.
Tip
See the research enablement wiki for more information on buckets.
-
D. R. Grimes, C. T. Bauch, and J. P. A. Ioannidis, “Modelling science trustworthiness under publish or perish pressure,”“ Royal Society Open Science, vol. 5, no. 1, p. 171511, Jan. 2018, doi: 10.1098/rsos.171511. ↩
-
M. Baker, “1,500 scientists lift the lid on reproducibility,”“ Nature, vol. 533, no. 7604, Art. no. 7604, May 2016, doi: 10.1038/533452a. ↩
-
A flat-file is a simple text file that contains data in a structured format, such as JSON or YAML. Flat-files are easy to read and write, and can be used to store configuration data for applications. ↩
ACORN Schemas and Ontologies
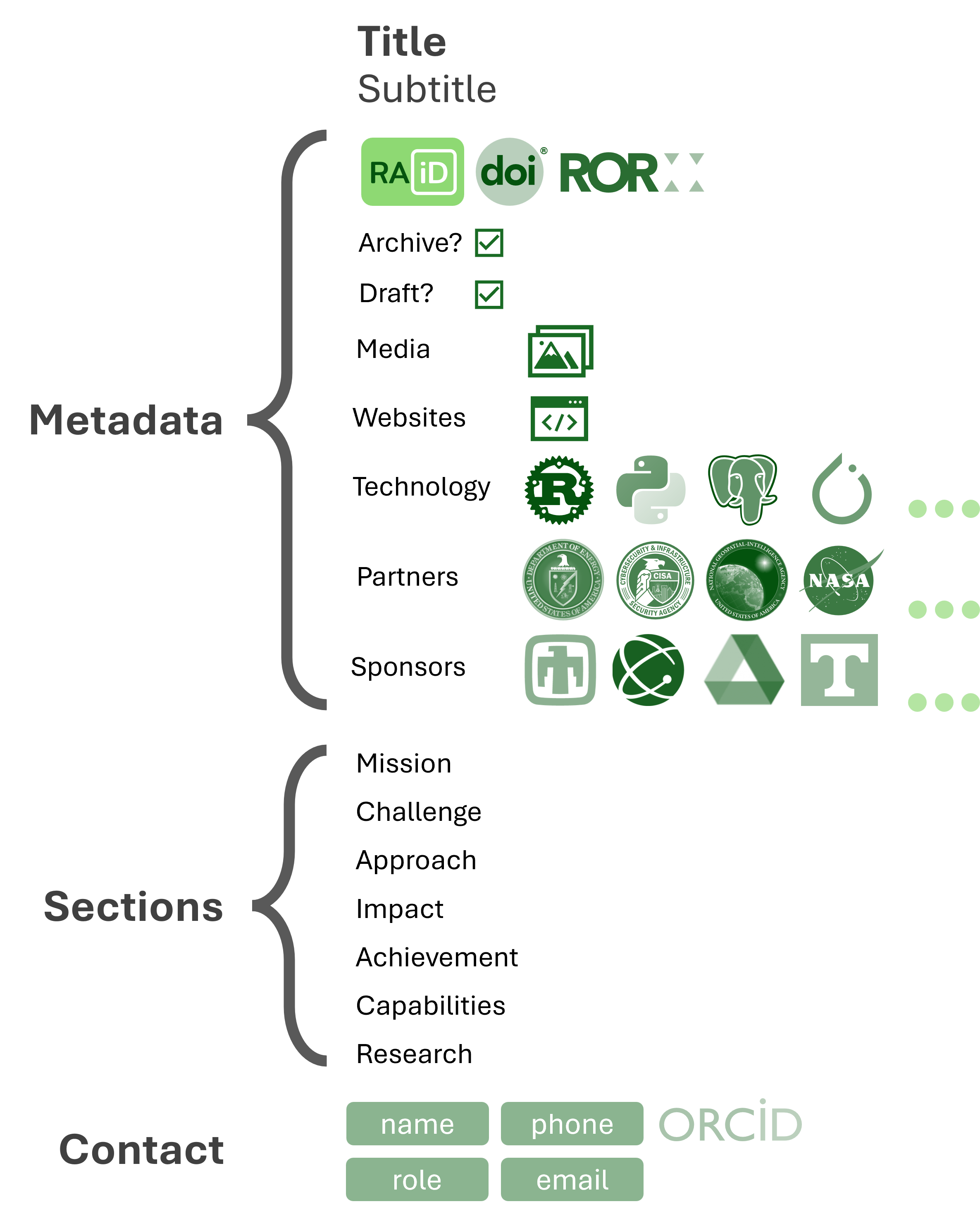
ASPECT
A Scientific Paradigm for the Efficient Classification of Technology

portability | maturity | autonomy | motivity
The ASPECT framework is a standardized methodology for classifying and describing technology. It defines underlying dimensions of technology and uses them to map projects into a shared space, allowing clearer insight into their capabilities, requirements, and relationships.
ASPECT was designed to unify our understanding of automation, AI/ML technology, and “classical” software. We focus on “technology” instead of “AI/ML technology” because the latter is a subset of the former. Focusing on AI/ML as the end goal is not fruitful or correct. In fact, doing so is backward. AI/ML software is not novel in any meaningful sense. Even if it was, it would still be 100% predicated on the scientific principles of software.
In the context of technology, AI/ML and automation are the same.
Tip
Key Components
Primary attributes
click arrow to expand or collapse
📦 Portability
- Limited (level 0)
- Source (level 1)
- Containerized (level 2)
- Installer (level 3)
- Package manager (level 4)
- WebAssembly (level 5)
🪴 Maturity
- Unvalidated (level 0)
- Discovery (level 1)
- Concept (level 2)
- Development (level 3)
- Prototype (level 4)
- Proven (level 5)
🤝 Autonomy
- Manual (level 0)
- Machine-assisted (level 1)
- Human-as-primary (level 2)
- Machine-as-primary (level 3)
- Human-supervised (level 4)
- Machine-only (level 5)
🦾 Motivity
- Inert (level 0)
- Computational (level 1)
- Perceptive (level 2)
- Projective (level 3)
- Reactive (level 4)
- Adaptive (level 5)
💾 Data
Data is not included in primary four attributes, but is very important when characterizing technology.
Data has multiple dimensions
- Real or Synthetic
- Availability
- Modality
- Quality
Example
The ASPECT framework can be applied in various scenarios
Consider a fictional project with the following characterization:
| Attribute | Level | Details |
|---|---|---|
| 📦 Portability | Level 1 | Source |
| 🪴 Maturity | Level 3 | Development |
| 🤝 Autonomy | Level 1 | Machine-assisted |
| 🦾 Motivity | Level 2 | Perceptive |
Badge Visualization
ASPECT can be visualized in a badge-like form for visual project portfolio management

Figure 1: ASPECT badge for a project
Figure 1 is an example of an ASPECT badge that provides immediate feedback on the state of the project and its technology components. It can be used in project dashboards, reports, and presentations to communicate the current status and future goals of the project in a clear and concise manner. Figure 2 below shows the same badge as depicted in figure 1, but with the attributes annotated for clarity.
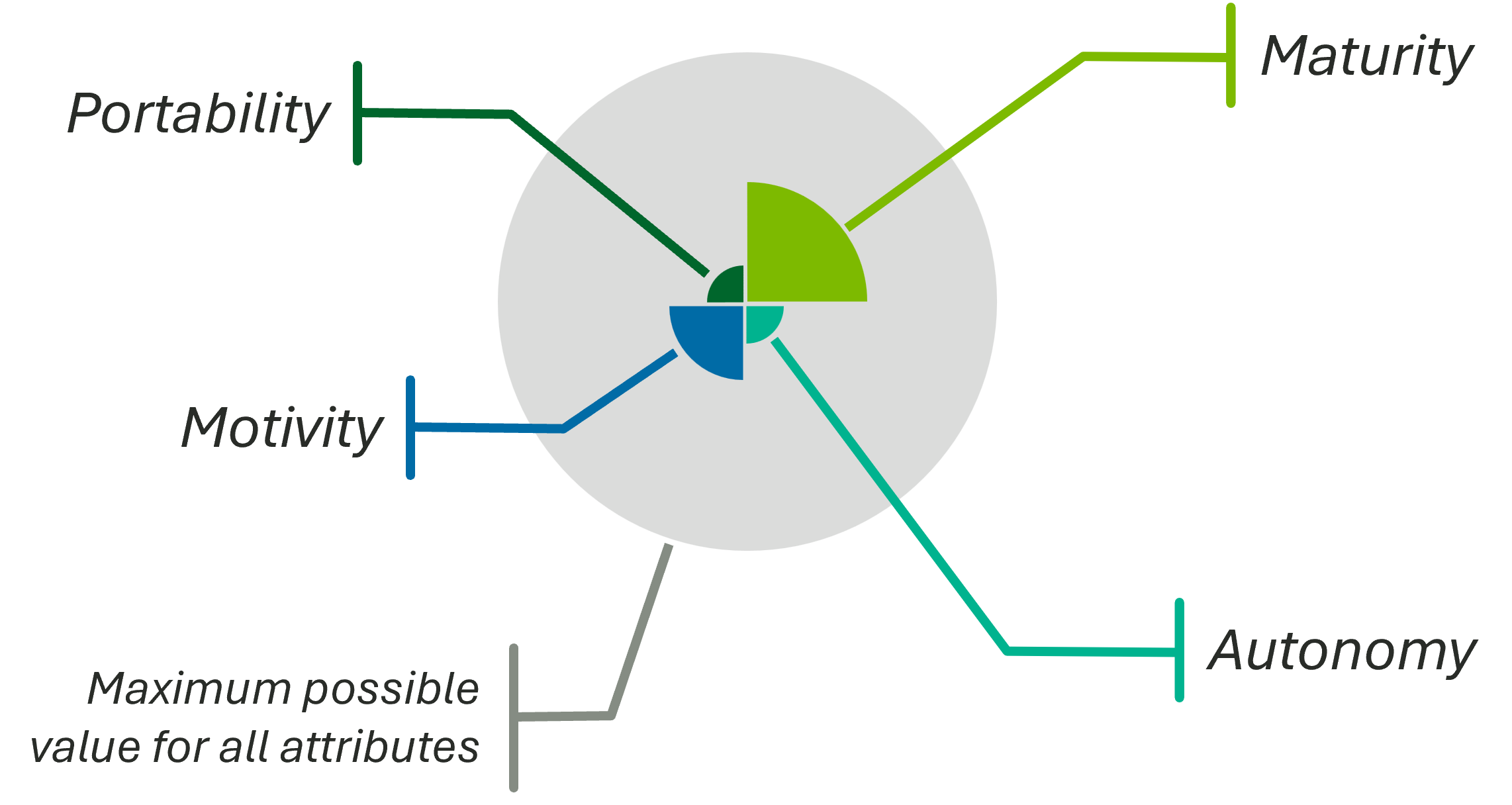
Figure 2: Annotated ASPECT badge
📦 Software Portability
Software portability describes how easily software can move across platforms and run in different environments with little or no modification. In ASPECT, this attribute helps measure whether software can work across different hardware, operating systems, and cloud setups.
Levels of Portability
Limited (Level 0)
Software at this level is tied to a specific environment. Running it elsewhere often requires major code or configuration changes. It may depend on platform-specific hardware, operating systems, or libraries that are hard to reproduce.
Source (Level 1)
Software at this level can be compiled and run on different platforms when the required compiler and build tools are available. In most cases, only minor changes are needed. Some platform-specific dependencies may still need attention during build or setup.
Containerized (Level 2)
Software at this level is packaged and run in containers such as Docker1, Podman2, or Apptainer3. Containers isolate dependencies and provide a consistent runtime. As a result, deployment and scaling are easier across local, on-premise, and cloud environments when a compatible container runtime is available.
Installable (Level 3)
Software at this level is designed to be installed and configured on multiple platforms, usually through installers or setup scripts. Some manual setup may still be required, but the process is generally user-friendly. Platform-specific installers or options are often provided to support different operating systems and hardware.
Automated Installation Available (Level 4)
Software at this level is distributed through one or more package managers such as npm4, Homebrew5, Scoop6, or the Ubuntu advanced package management tool7. It is typically published to package repositories so users can install and update it with standard tools. This approach improves deployment speed and ongoing maintenance across many environments.
WebAssembly8 (Level 5)
Software at this level is compiled to WebAssembly (WASM)9, which allows it to run in modern browsers and other environments that support a WebAssembly runtime. It can often run across desktop, mobile, and server targets without platform-specific changes. Because runtime support is broad and growing, WebAssembly is often treated as a leading portability target.
🤝 Autonomy
In the context of ASPECT, “autonomy” characterizes a technology’s level of human-machine teaming (HMT) and describes the adaptive, bi-directional interaction among humans and machines that augments human capabilities for improved outcomes. This attribute builds on prior work by the Society of Automotive Engineers’ six levels of driving automation1 and expands on ISO definitions to partition technology into distinct and employable categories.
Tip
ISO 229892 defines human-machine teaming as “integration of human interaction with machine intelligence capabilities.”
This attribute is important for understanding how well a technology can operate independently of human intervention, as well as the level of human oversight and control required for its operation. By categorizing technologies based on their autonomy, we can better understand their capabilities and limitations and make informed decisions about their use in various applications. The Visidata project popularized its own similar “level of machine assistance” characterizing LLM involvement in code changes3, and ASPECT’s autonomy attribute builds on this work to provide a more comprehensive framework for understanding the relationship between humans and machines in technology.
Tip
The
acorn-libcrate provides conversion utilities to seemlessly integrate Visidata’s AI collaboration levels into ASPECT’s autonomy attribute.
Levels
Manual (HMT 0)
This level is characterized by the execution of a script where the deterministic outcome is fully known and controlled by the human operator.
Machine-assisted (HMT 1)
In this level, the machine assists the human operator in executing a task. The human remains in full control of the task execution, with the machine offering support or suggestions as needed. This might include an iterative script that augments the input during each iteration based on prior outputs.
Human as primary (HMT 2)
Machine as primary (HMT 3)
Human supervisor (HMT 4)
Machine only (HMT 5)
-
SAE J3016 Taxonomy and Definitions for Terms Related to Driving Automation Systems: https://www.sae.org/standards/j3016_202104-taxonomy-definitions-terms-related-driving-automation-systems-road-motor-vehicles ↩
-
ISO/IEC 22989:2022 Information Technology — Artificial Intelligence Concepts and Terminology ↩
-
Visidata AI Collaboration Levels: https://www.visidata.org/blog/2026/ai/ ↩
🪴 Maturity
Levels
| Maturity Level | TRL Mapping | Description |
|---|---|---|
| Unvalidated | N/A | Technology has not been assessed or lacks sufficient evidence of readiness. |
| Discovery | 0-1 | Early exploration and basic research to establish foundational principles. |
| Concept | 2-3 | Concept is defined and initial feasibility is demonstrated. |
| Development | 4-5 | Technology is built and validated through low- to high-fidelity development. |
| Prototype | 6-8 | Working prototype is demonstrated in a relevant environment through operational integration. |
| Proven | 9 | System is proven through successful real-world operation. |
Tip
Discussion
ASPECT leverages a simplified mapping from augmented technology readiness levels (TRL). Wikipedia1 defines TRLs as “a method for estimating the maturity of technologies during the acquisition phase of a program. TRLs enable consistent and uniform discussions of technical maturity across different types of technology.” The U.S. federal acquisitions community widely uses TRLs to assess the maturity of a particular technology. Additionally, ASPECT incorporates work2 that adapted TRLs to directly address the particular nuances of machine learning systems. Additionally, ASPECT maturity levels work well with the capability maturity model but go beyond maintenance processes and efficiency to characterize a technology’s maturity in practice. Specifically, ASPECT’s openness and portability attributes create a well-defined understanding of a given technology.
Maturity in ASPECT reflects the degree to which a system has been tested, validated, and proven in real-world scenarios, as well as its readiness for deployment and integration into existing workflows. In combination with the other ASPECT attributes, ASPECT’s maturity attribute provides a holistic view of the system under consideration, beyond a technology’s age or quality.
-
Technology Readiness Level: https://en.wikipedia.org/wiki/Technology_readiness_level
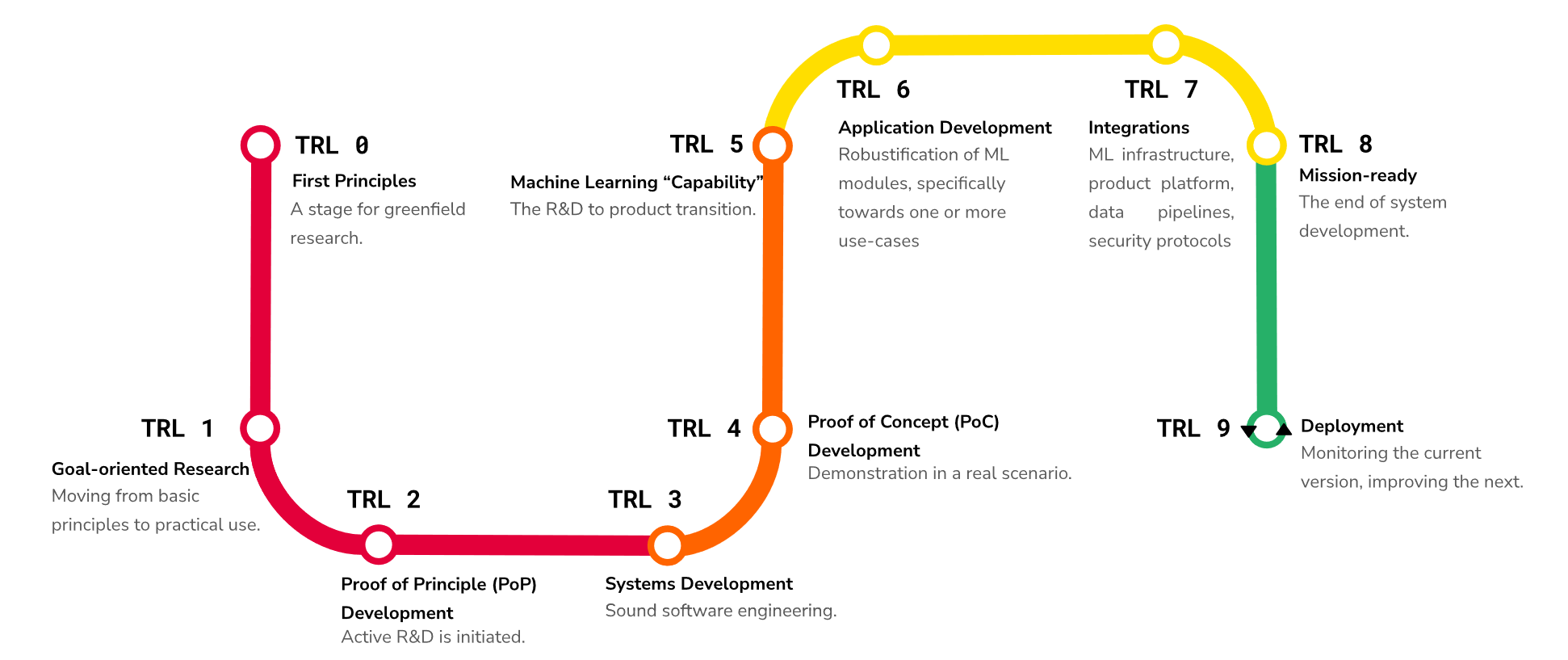 ↩
↩ -
A. Lavin et al., “Technology readiness levels for machine learning systems,” Nat Commun, vol. 13, no. 1, p. 6039, Oct. 2022, doi: 10.1038/s41467-022-33128-9. ↩
🦾 Motivity
Discussion
“Motivity” is a technology’s ability to exert power over its environment. In the context of ASPECT, this involves how a given technology interacts with its environment and its degree of autonomy in performing tasks. As a model of interaction, motivity is closely related to the autonomy attribute. Motivity can also be viewed in terms of data binding: no binding, one-way binding, and two-way binding.
Motivity is a somewhat uncommon word. It was chosen for the ASPECT framework in part because deliberate ambiguity can foster conceptual depth. Rarity minimizes external preconceptions, enabling custom meaning layering without the baggage of a widely used term.
Motivity has been defined in various contexts across philosophy, biology, and psychology, often emphasizing intrinsic capacity for motion or change, which makes sense considering its etymology, emphasizing an intrinsic ability rather than external force. Motivity uniquely captures an inherent “motive power” or self-initiating force for change, aligning with a data model’s bidirectional synchronization as an active, propulsive property rather than passive reactivity (which implies response) or linkage (structural connection).
Similar niche terms like “affordance” in HCI gained traction despite initial obscurity and today offer rich, nuanced meanings.
Levels
Motivity is partitioned into six ordinal levels that describe how a technology interacts with its environment. The framework is built around three primitives: perception (one-way input binding), projection (one-way output binding), and comprehension (internal state and computation).
Note
Throughout this document, “comprehension” refers to a technology’s ability to receive, store, and act on data — not to general intelligence, consciousness, or AGI. A hash function, a state machine, and a lookup table all exhibit comprehension in this sense: they maintain internal state and their behavior depends on it.
| Level | Name | Perception | Comprehension | Projection | Stateless/Stateful | Examples |
|---|---|---|---|---|---|---|
| 0 | Inert | ✗ | ✗ | ✗ | — | A hammer or simple pulley system |
| 1 | Computational | ✗ | ✓ | ✗ | Stateful (internal) | Digital model1, simulation |
| 2 | Perceptive | ✓ | ✗ | ✗ | Stateless | Data shadow1, sensor log |
| 3 | Projective | ✗ | ✗ | ✓ | Stateless | Cron job that emails status |
| 4 | Reactive | ✓ | ✗ | ✓ | Stateless | Smart light switch, relay |
| 5 | Adaptive | ✓ | ✓ | ✓ | Stateful | Digital twin1, autonomous agent |
Inert (Level 0)
Technology at this level has no computational capability and no interaction with the environment. It is purely passive. Examples include a hammer, a simple pulley system, or any purely physical tool with no embedded intelligence.
Computational (Level 1)
Technology at this level performs self-contained computation but has no input from or output to the environment. Comprehension (internal processing) is present, but neither perception nor projection are. Examples include a digital model or simulation that runs in isolation.
Perceptive (Level 2)
Technology at this level receives input from the environment (one-way input binding) but produces no output and has no internal comprehension. The technology observes but does not process or act. Examples include a data shadow or a sensor that logs readings to storage without analyzing them.
Projective (Level 3)
Technology at this level produces output to the environment (one-way output binding) but receives no input and has no internal comprehension. Examples include a cron job that emails a status report — it projects information without sensing or reasoning about its environment.
Reactive (Level 4)
Technology at this level has two-way binding with the environment (perception and projection) but is stateless — it responds to input with output in a direct stimulus-response fashion with no internal model or memory of past interactions. Comprehension is absent. Examples include a smart light switch that turns lights on when motion is detected, or a relay that closes a circuit when a threshold is crossed.
Adaptive (Level 5)
Technology at this level has full two-way binding (perception and projection) with internal comprehension — it maintains state, builds an internal model of its environment, and changes its behavior based on accumulated experience. Examples include a digital twin that continuously synchronizes with a physical system and predicts future states, or an autonomous agent that plans and adapts.
-
Y. K. Liu, S. K. Ong, and A. Y. C. Nee, “State-of-the-art survey on digital twin implementations,” Adv. Manuf., vol. 10, no. 1, pp. 1-23, Mar. 2022, doi: 10.1007/s40436-021-00375-w. ↩ ↩2 ↩3
💾 Data
Discussion
When discussing data, we can evaluate four core aspects:
- Origin — Where does the data come from, and how was it produced?
- Availability — How accessible is the data to intended users and systems?
- Modality — What forms of information does the data contain?
- Quality — How well does the data support its intended use?
Attributes
Origin
Data origin describes whether the data is collected from real-world observations (real) or generated synthetically (synthetic). Real data is often considered more valuable for certain applications, such as training machine learning models, because it captures the complexity and variability of the real world. However, synthetic data can be useful for testing, simulation, and augmenting real datasets, especially when real data is scarce or sensitive.
NVIDIA Omniverse Replicator1 is an example of a tool that can generate synthetic data, particularly in the context of computer vision and robotics. By creating realistic virtual environments and scenarios, it allows researchers to generate large amounts of labeled data without costly and time-consuming real-world data collection.
Availability
Availability describes the extent to which data can be accessed and used. It is strongly related to “openness” and the “presumed open principle” for data.
While openness is characterized as open, public, shared, or closed, ASPECT data availability takes a more direct approach to describing the actual availability of data, which may be “open” but still unavailable due to other factors (e.g., technical or legal barriers).
Modality
Data modality describes the type or format of data, which can include:
- 📕 Text — Unstructured or structured textual data, such as documents, articles, or social media posts
- 🎵 Audio — Sound recordings, such as music, speech, or environmental sounds
- 🖼️ Image — Visual data, such as photographs or scanned images
- 🎬 Video — Moving image data, such as movies or surveillance footage
- 📈 Signal — Time-series data, such as sensor readings or financial market data
- 🕸️ Graph — Structured data representing relationships between entities, such as social networks or knowledge graphs
Multi-modal data combines multiple modalities, such as video with audio or text with images, to provide richer context and insights. In the context of ASPECT, data modality is a list, and multi-modal data can be described by including multiple modalities in the list (e.g., [“text”, “image”] for research activity data that relies on both textual and visual data).
Quality
Data quality leverages a precious metals metaphor to describe data quality.
Data quality describes the level of processing and readiness of the data for analysis and use. The levels were developed with inspiration from data readiness levels 2, anaylsis-ready data3, and multiple other data quality frameworks. For example, the transition from gold to platinum maps nearly directly to a transition from band B to band A in the data readiness levels. The key difference is ASPECT’s quality levels are more intuitive and directly actionable for researchers working with data in the context of research activities. See the geospatial data section below for an example of how data processing levels relates to data quality.
🌎 Geospatial Data
Geospatial data describes features and events tied to location. Common formats include raster data, such as satellite imagery, and vector data, such as points, lines, and polygons. These datasets support mapping, navigation, and spatial analysis. For geospatial work, data processing level is an important additional quality dimension.
Based on NASA’s Data Processing Levels4, geospatial data can be described with the following processing levels
- Level 0 — Raw
- Level 1A — Annotated
- Level 1B — Processed Annotated
- Level 1C — Spectral Variables
- Level 2 — Derived Geophysical
- Level 2A — Derived Surface
- Level 2B — Processed Derived Surface
- Level 3 — Gridded
- Level 3A — Periodic Summaries
- Level 4 — Model Output
Most remote sensing sources (e.g. satellites) provide metadata that includes the data processing level. Processing the geospatial data with techniques such as atmospheric correction, pansharpening, and orthorectification can improve the quality and usability of the data for various applications, thereby increasing the associated processing level. For example, orthorectification corrects for terrain-induced distortions, improving the spatial accuracy of the data and increasing its processing level from Level 1B to Level 2B.
Geospatial data processing level relates to ASPECT’s data quality attribute in that higher processing levels typically indicate higher quality data. For instance, Level 2B data, which has been processed to correct for atmospheric effects and terrain distortions, would generally be considered higher quality than Level 1B data, which is only annotated and not fully processed. However, the specific quality designation (e.g., gold, silver) would depend on additional factors such as the use case and the presence of any remaining artifacts or limitations in the data. For example, orthorectification might be the difference between gold and silver quality data for AI/ML applications.
-
NVIDIA Omniverse Replicator: https://docs.omniverse.nvidia.com/extensions/latest/ext_replicator.html ↩
-
Data Readiness Levels: https://arxiv.org/abs/1705.02245 ↩
-
Analysis Ready Data (ARD): https://ieeexplore.ieee.org/document/8899846 ↩
-
NASA Data Processing Levels: https://www.earthdata.nasa.gov/learn/earth-observation-data-basics/data-processing-levels ↩
Citations
A selection of academic papers and resources that have influenced the development of ACORN
[1] E. Njor, M. A. Hasanpour, J. Madsen, and X. Fafoutis, “A Holistic Review of the TinyML Stack for Predictive Maintenance,” IEEE Access, vol. 12, pp. 184861-184882, 2024, doi: 10.1109/ACCESS.2024.3512860.
[2] Y. Yang et al., “A Survey of AI Agent Protocols,” Apr. 26, 2025, arXiv: arXiv:2504.16736. doi: 10.48550/arXiv.2504.16736.
[3] B. Liu et al., “Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems,” Mar. 31, 2025, arXiv: arXiv:2504.01990. doi: 10.48550/arXiv.2504.01990.
[4] “AI Blindspot: A Discovery Process for preventing, detecting, and mitigating bias in AI systems.” Accessed: Jan. 24, 2023. [Online]. Available: https://aiblindspot.media.mit.edu/
[5] V. Gadepally et al., “AI Enabling Technologies: A Survey,” May 08, 2019, arXiv: arXiv:1905.03592. doi: 10.48550/arXiv.1905.03592.
[6] A. Jain, S. Sharma, and S. Duggal, “Comparative Study of Various Process Model in Software Development,” 2013. Accessed: Jan. 24, 2023. [Online]. Available: semanticscholar.org
[7] Q. Hua et al., “Context Engineering 2.0: The Context of Context Engineering,” Oct. 30, 2025, arXiv: arXiv:2510.26493. doi: 10.48550/arXiv.2510.26493.
[8] N. D. Lawrence, “Data Readiness Levels,” May 05, 2017, arXiv: arXiv:1705.02245. doi: 10.48550/arXiv.1705.02245.
[9] A. Fuller, Z. Fan, C. Day, and C. Barlow, “Digital Twin: Enabling Technologies, Challenges and Open Research,” IEEE Access, vol. 8, pp. 108952-108971, 2020, doi: 10.1109/ACCESS.2020.2998358.
[10] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge Distillation: A Survey,” Int J Comput Vis, vol. 129, no. 6, pp. 1789-1819, June 2021, doi: 10.1007/s11263-021-01453-z.
[11] D. Kreuzberger, N. Kühl, and S. Hirschl, “Machine Learning Operations (MLOps): Overview, Definition, and Architecture,” May 14, 2022, arXiv: arXiv:2205.02302. doi: 10.48550/arXiv.2205.02302.
[12] M. Mitchell et al., “Model Cards for Model Reporting,” in Proceedings of the Conference on Fairness, Accountability, and Transparency, Jan. 2019, pp. 220-229. doi: 10.1145/3287560.3287596.
[13] E. Blasch, J. Sung, and T. Nguyen, “Multisource AI Scorecard Table for System Evaluation,” Feb. 07, 2021, arXiv: arXiv:2102.03985. doi: 10.48550/arXiv.2102.03985.
[14] F. Yu, H. Zhang, and B. Wang, “Natural Language Reasoning, A Survey,” Mar. 26, 2023, arXiv: arXiv:2303.14725. doi: 10.48550/arXiv.2303.14725.
[15] S. Zhao, Y. Yang, Z. Wang, Z. He, L. K. Qiu, and L. Qiu, “Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely,” Sept. 23, 2024, arXiv: arXiv:2409.14924. Accessed: Oct. 02, 2024. [Online]. Available: arxiv.org
[16] Y. K. Liu, S. K. Ong, and A. Y. C. Nee, “State-of-the-art survey on digital twin implementations,” Adv. Manuf., vol. 10, no. 1, pp. 1-23, Mar. 2022, doi: 10.1007/s40436-021-00375-w.
[17] Center for Security and Emerging Technology and B. Buchanan, “The AI Triad and What It Means for National Security Strategy,” Center for Security and Emerging Technology, Aug. 2020. doi: 10.51593/20200021.
[18] J. M. Bradshaw, R. R. Hoffman, D. D. Woods, and M. Johnson, “The Seven Deadly Myths of ‘Autonomous Systems,’” IEEE Intelligent Systems, vol. 28, no. 3, pp. 54-61, May 2013, doi: 10.1109/MIS.2013.70.
[19] M. R. Endsley, “Toward a Theory of Situation Awareness in Dynamic Systems. Human Factors Journal 37(1), 32-64,” ResearchGate, Aug. 2025, doi: 10.1518/001872095779049543.
Command Line Reference
█████████ █████████ ███████ ███████████ ██████ █████
███▒▒▒▒▒███ ███▒▒▒▒▒███ ███▒▒▒▒▒███ ▒▒███▒▒▒▒▒███ ▒▒██████ ▒▒███
▒███ ▒███ ███ ▒▒▒ ███ ▒▒███ ▒███ ▒███ ▒███▒███ ▒███
▒███████████ ▒███ ▒███ ▒███ ▒██████████ ▒███▒▒███▒███
▒███▒▒▒▒▒███ ▒███ ▒███ ▒███ ▒███▒▒▒▒▒███ ▒███ ▒▒██████⠀
▒███ ▒███ ▒▒███ ███▒▒███ ███ ▒███ ▒███ ▒███ ▒▒█████
█████ █████ ▒▒█████████ ▒▒▒███████▒ █████ █████ █████ ▒▒█████⠀
▒▒▒▒▒ ▒▒▒▒▒ ▒▒▒▒▒▒▒▒▒ ▒▒▒▒▒▒▒ ▒▒▒▒▒ ▒▒▒▒▒ ▒▒▒▒▒ ▒▒▒▒▒
⠀⠀⠀⠀⠀⠀⠀⠀~ Accessible Content Optimization for Research Needs ~⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀
Usage: acorn [FLAGS] [COMMAND]
COMMANDS:
check Perform static analysis on research activity data and apply standardized best practices
doctor Diagnose and correct system requirements for using acorn
download Download research activity data from buckets
export Export research activity data to a specific target
format Format research activity data in place (inherently includes some elements of `acorn check`)
link Add linked data context to research activity data
schema Print research activity data or research activity identifier metadata JSON schema to stdout
help Print this message or the help of the given subcommand(s)
FLAGS:
-X, --offline
Prevent communication with the internet - intended for disconnected, local environments
Note: Use of --offline may require extra configuration options for certain commands
-t, --threads <N>
Limit number of threads used by Rayon for parallel processing
See Rayon documentation for more information
[default: 0]
-v, --verbose...
Increase logging verbosity
-q, --quiet...
Decrease logging verbosity
-V, --version
Print version information
-h, --help
Print help (see a summary with '-h')
Configuration
Flat file
ACORN can be configured using JSON or YAML format flat files. These configuration files allow users to specify options and settings for the ACORN CLI tool, including input and output directories and logging levels.
Example
.acorn.json file
{
"buckets": [
{
"name": "bessd",
"repository": {
"provider": "gitlab",
"id": 17603,
"uri": "https://code.ornl.gov/research-enablement/buckets/bessd"
}
},
{
"name": "ccsd",
"repository": {
"provider": "gitlab",
"id": 17602,
"uri": "https://code.ornl.gov/research-enablement/buckets/ccsd"
}
},
{
"name": "nssd",
"repository": {
"provider": "gitlab",
"id": 17410,
"uri": "https://code.ornl.gov/research-enablement/buckets/nssd"
}
}
]
}
Tip
.acorn.jsonis the default configuration file name the ACORN tool looks for in the current working directory. You can also specify a different configuration file using the--config <FILE>flag when running ACORN commands.
.env file and Environment Variables
The ACORN CLI tool can also be configured using .env files and/or environment variables.
Example
.env file
ACORN_LOG_LEVEL=info
READABILITY_METRIC=ari
MAX_ALLOWED_ARI=12
Commands
Command Workflow
stateDiagram
direction LR
[*] --> RAD: create
RAD --> check
check --> RAD
check --> format
format --> link
format --> export
🕵️♂️ Audit
Provides a holistic report on research activity data compliance with ACORN content and grammar rules. e.g.,“75% of research activity data in NSSD bucket has an acceptable readability score.”
Warning
This documentation is a work in progress. Some sections may be incomplete or subject to change.
✅ Check
Perform checks on associated research activity data to ensure consistency, readability, and easy analysis.
Example Use
# Check a specific research activity index
acorn check path/to/project/index.json
# Check all research activity data in a directory
acorn check path/to/project/
Check Categories
- 🏛️ Schema Validation: Ensure that all data files conform to the expected schema
- ✨ Prose Quality: Analyze written content for standards such as grammar, spelling, and word counts
- 👓 Readability: Evaluate readability of written content using established metrics1
- 🔗 Link Integrity: Verify all hyperlinks within the content are valid and reachable
- 📊 Data Consistency: Check for dataset consistency and completeness
- 🚦 Convention Adherence: Ensure compliance with naming conventions and organization-specific standards
Customization Options
The check command supports several flags and options to customize its behavior (e.g., skipping certain checks, disabling certain behaviors, etc.)
Include --exit-on-first-error to stop execution upon encountering the first error.
Bypass verifying the checksum of downloaded artifacts with --skip-verify-checksum2
Skip Checks
--skip schema: Skip schema validation checks--skip prose: Skip prose quality checks--skip readability: Skip readability checks--skip schema,prose: Skip both schema validation and prose quality checks (this works for any combination of categories)--disable-website-checks: Disable all website-related checks (link integrity, etc.)
Note
--disable-website-checksis redundant whenacorn --offlineis used for commands that need to be run in offline environments.
Configure Readability
Readability can be configured for desired metric and level by passing options directly to the command line or via a .env file. Command line options override .env settings.
--readability-metric <METRIC>: Specify which readability metric to use- Set
READABILITY_METRICin your.envfile to choose the readability metric. Default metric isfkgl(Flesch-Kincaid Grade Level). - Set
MAX_ALLOWED_FKGLin your.envfile to define the maximum acceptable FKGL score. Each metric has its own corresponding maximum score variable (e.g.,MAX_ALLOWED_ARIfor Automated Readability Index).
Example .env file
Configure ACORN to use the Coleman-Liau Index (CLI) readability metric with a maximum allowed score of 14.0 (default value is 12.0):
READABILITY_METRIC=cli
MAX_ALLOWED_CLI=14.0
-
See the readability module documentation for a full list of available readability metrics. ↩
-
⚠️ Skipping checksum verification may expose you to security risks. Use this option with caution. ↩
👨⚕️ Doctor
Diagnose and fix issues with host environment to enable optimal ACORN functionality
Warning
This documentation is a work in progress. Some sections may be incomplete or subject to change.
📥 Download
Obtain files from an ACORN bucket to use in your local file system
- See the configuration documentation for details on configuring ACORN commands.
- By default,
downloadwill save files to./contentin the working directory unless an output path is specified via the--outputflag.
Example Usage
# Download research activity data from a single bucket repository URL
acorn download https://code.ornl.gov/research-enablement/buckets/nssd
# Download research activity data from a list of buckets
acorn download --config /path/to/.acorn.json
# Download research activity data to a specific output directory
acorn download --config /path/to/.acorn.yml --output /path/to/output
Local vs Remote
The download command copies files from a local ACORN bucket when local file:// URIs are used for associated buckets in the configuration file. Use "git" as the provider for local buckets.
"buckets": [
{
"name": "test (local)",
"repository": {
"provider": "git",
"location": "file:./tests/fixtures/data/bucket/"
}
},
{
"name": "nssd (remote)",
"repository": {
"provider": "gitlab",
"location": {
"scheme": "https",
"uri": "https://code.ornl.gov/research-enablement/buckets/nssd"
}
}
}
]
GitLab vs GitHub
The download command supports both GitLab and GitHub remote repositories for ACORN buckets. The configuration for each is similar, with the main difference being the provider field in the repository object.
"buckets": [
{
"name": "ccsd (gitlab)",
"repository": {
"provider": "gitlab",
"id": 17410,
"uri": "https://code.ornl.gov/research-enablement/buckets/ccsd"
}
},
{
"name": "test (github)",
"repository": {
"provider": "github",
"uri": "https://github.com/jhwohlgemuth/bucket"
}
}
]
📤 Export
Export research activity data to various formats for analysis and sharing
This command allows you to export research activity data from ACORN into formats such as PDF, Markdown, YAML, or PPTX. With export, you can easily share your research with sponsors, collaborators, or the general public in a variety of contexts.
export supports exporting individual research activity indices or entire directories containing multiple indices.
ACORN allows you to maintain research activity data as persistent, interconnected single sources of truth. As such, you can easily create a variety of output artifacts while ensuring consistency and accuracy across all selected formats.
graph LR
data("JSON</br>(index.json)") --> export{Export}
export --> PDF("PDF</br>(fact sheet)")
export --> PPTX("PPTX</br>(presentation)")
export --> Convert("JSON | YAML | Markdown</br>(add to project)")
export --> BAG("BagIt</br>(archive)")
export --> more("More to come...</br>(Markdown, YAML, etc.)")
Tip
You can see some export command results by visiting the ORNL Research Activity Index, which features a variety of research activity data presented in different formats.
Example Usage
# Export research activity data to PDF fact sheet
acorn export /path/to/index.json --format pdf
# Create PowerPoint presentations from all research activity data in a directory
acorn export /path/to/project/ --format powerpoint
Note
Each export format uses the
--outputoption to specify the output file or directory path. If not provided, ACORN will generate a default output path based on the input path and selected format. For example,--format pdfand--format powerpointwill generate files in the default export location (./export/) with names based on the project parent folder(s),--format bagwill add.zipto the output path (i.e.,--output ./exportwill create./export.zipand--output /path/to/bagwill create/path/to/bag.zip).
PowerPoint Reference Template
Customize the PowerPoint export by providing a reference template using the --reference option. This allows you to define specific styles, layouts, and branding for your presentations.
acorn export /path/to/index.json \
--format powerpoint \
--reference /path/to/reference.pptx
The reference template allows you to specify which values are used and where, using placeholder text in the format {{ PLACEHOLDER_NAME }}. During export, ACORN will replace these placeholders with corresponding data from the associated research activity data. You can find an example PowerPoint reference template in the ACORN GitLab repository.
Available Placeholders
The following placeholders can be used in your PowerPoint reference template:
String values
caption- First image captionchallenge- Challenge descriptioncitation- DOI citationemail- Contact emailfirst- Contact first namefocus- Research focus arealast- Contact last namemanagers- Manager names (joined with"and")missionnotes- Presentation notes (intended to be added PowerPoint speaker notes)partners- Partner names (joined with", ")programs- Program names (joined with"and")subtitletitle
Lists (bullet points)
achievementareas- Research areasimpacttechnical- Technical approach
🤖 Format
Auto-fix and format research activity data (RAD) files to maintain consistency, resolve values, and improve prose quality
Example Usage
# Format a specific research activity index
acorn format path/to/project/index.json
# Format all research activity data in a directory
acorn format path/to/project/
# Preform dry-run to see proposed changes without modifying files
acorn format path/to/project/index.json --dry-run
Example Output
meta:
keywords:
- - automatin
+ - automation
technology:
- - JavaScript
- - TypeSpec
- astro
+ - javascript
- react
- - rs
+ - rust
+ - typespec
sponsors:
- - DOD
+ - Department of Defense
...
contact:
jobTitle: Primary Investigator
givenName: Jasdrey
familyName: Wohlson
email: me@example.com
- telephone: '(123) 456-7890'
+ telephone: '123.456.7890'
url: https://www.ornl.gov/staff-profile/jason-h-wohlgemuth
- organization: GSHS
+ organization: Geospatial Science and Human Security Division
+ affiliation: National Security Sciences Directorate
Features
- 🛠️ Auto-fixing: Automatically fix common inconsistencies in RAD structure and prose
- 🎨 Consistent Formatting: Ensure consistent JSON formatting across all data files
- 🩹 Resolve Values: Resolve certain values against controlled vocabularies to ensure correct meaning
- 🖼️ Resolve missing images: Find first image in associated RAD folders and add to metadata if missing
Resolved Values
meta.keywords: Resolve keywords against ACORN Keywords Vocabularymeta.technology: Resolve technology against ACORN Technology Vocabularymeta.partners: Resolve partner names against ACORN Partners Vocabularymeta.sponsors: Resolve sponsor names against ACORN Sponsors Vocabularycontact.organization: Resolve organization name against a given org chart (currently only supports ORNL org chart)contact.affiliation: Resolve organization name against a given org chart (currently only supports ORNL org chart)
Examples
- Keywords:
"ai"→ resolves to"artificial-intelligence" - Partners:
"NREL"→ resolves to"National Renewable Energy Laboratory" - Technologies:
"rs"→ resolves to"rust" - Sponsors:
"Dept. of Energy"→ resolves to"Department of Energy"
🕸️ Link
Add linked data context to research activity data (RAD) and create
JSON-LDdocuments
The link command augments user-input RAD with linked data context and outputs JSON-LD documents. This process involves mapping the input data to established ontologies and vocabularies, thereby enhancing its interoperability and depth of meaning.
ACORN helps prepare RAD for programmatic expansion. The link command makes input RAD machine-readable.
Tip
Linked Data creates a connected network of standards-based, machine-readable data across Web sites.
Example Usage
# Link a specific research activity index
acorn link path/to/project/index.json
# Link all research activity data in a directory
acorn link path/to/project/
Tip
The
linkcommand is almost identical to theformatcommand, complete with support for the--dry-runflag to preview changes without creating files.
Example Output
"contact": {
+ "@context": {
+ "jobTitle": "https://schema.org/jobTitle",
+ "givenName": "https://schema.org/givenName",
+ "familyName": "https://schema.org/familyName",
+ "identifier": "https://orcid.org",
+ "email": "https://schema.org/email",
+ "telephone": "https://schema.org/telephone",
+ "url": "https://schema.org/url",
+ "organization": "https://schema.org/worksFor",
+ "affiliation": "https://schema.org/affiliation"
+ },
+ "@type": "https://schema.org/person",
"jobTitle": "Primary Investigator",
"givenName": "Audson",
"familyName": "Cargohlmuth",
"email": "wohlgemuthjh@ornl.gov",
"telephone": "865.576.7658",
"url": "https://www.ornl.gov/staff-profile/jason-h-wohlgemuth",
"organization": "Geospatial Science and Human Security Division",
"affiliation": "National Security Sciences Directorate"
}
📦 Packages
To enable broad adoption of ACORN, we provide packages for multiple popular programming contexts.
graph LR
A["acorn-lib</br>(Rust crate)"] -->|" is dependency of "|B["acorn-cli</br>(Rust crate)"]
A -->|"generates</br> bindings for "|C["acorn-py</br>(Python package)"]
A -->|"transpiles</br> API subset to "|D["acorn-web</br>(WASM package)"]
🦀 Rust crate
![]()
![]()
The ACORN CLI application is built on top of the acorn-lib Rust crate. The acorn-lib library provides core functionalities for working with ACORN schemas, validating persistent identifiers1, and generating artifacts.
Important
When ACORN validates a PID, it does not just use regular expressions, but also includes checksum validation when part of the associated PID specification. ARKs2, ISBNs3, ORCiDs4, and RORs5 all include some form of checksum, and
acorn-libvalidates these as well to ensure the PID is not only well-formed but also valid according to its specification.
Installation
-
Add
acorn-libas a dependency6cargo add acorn-lib -
Use
acorn-libfunctions in your Rust code#![allow(unused)] fn main() { use acorn::schema::validate::{is_ark, is_doi, is_orcid, is_ror}; assert!(is_ark("ark:/1234/w5678")); assert!(is_doi("10.11578/dc.20250604.1")); assert!(is_orcid("https://orcid.org/0000-0002-2057-9115")); assert!(is_ror("01qz5mb56")); } -
If you want to use the full capability of
acorn-libto build your own CLI app, be sure to enable thedoctorandpowerpointfeatures7cargo add acorn-lib --features doctor,powerpoint
-
Persistent Identifiers (PIDs) supported by
acorn-libinclude DOIs, ORCIDs, RAiDs, RORs, and ARKs. ↩ -
See the Cargo.toml for more details. ↩
🐍 Python Bindings
ACORN seeks to meet scientists where they are in all aspects. This includes the programming languages they use. The acorn-py package provides Python bindings to the core ACORN functionalities provided by the acorn-lib Rust crate.
Installation
- See the PyPI page for installation and usage instructions
- Use
acorn-libfunctions in Pythonfrom acorn.schema.validate import is_ark, is_doi, is_orcid, is_ror assert is_ark("ark:/1234/w5678") assert is_doi("10.11578/dc.20250604.1") assert is_orcid("https://orcid.org/0000-0002-2057-9115") assert is_ror("01qz5mb56")
Working with scientific artifact identifiers
The acorn-py package provides tools to work with common scientific artifact identifiers such as DOIs, ARKs, ORCIDs, and RORs and other indirectly related identifiers such as patent numbers and books (e.g., ISBNs). You can validate these identifiers, work with their components, and even extract them from text.
Tip
See the acorn-lib documentation for more details on persistent identifiers and how to work with them in your code.
Example
Find all patent numbers in a string
🐍 Python
from acorn.schema.pid import Patent
text = "The patent number for my work is US1234567B1."
values = Patent.find_all(text)
patent = values[0]
assert str(patent) == "US 1234567 B1"
assert patent.country_code == "US"
assert patent.serial_number == "1234567"
assert patent.kind_code == "B1"
🦀 Rust
#![allow(unused)]
fn main() {
use acorn::schema::pid::Patent;
let text = "The patent number for my work is US1234567B1.";
let values = Patent::find_all(&text);
let patent = values[0];
assert_eq!(patent.to_string(), "US 1234567 B1");
}API Consistency
The acorn-py API strives to adhere to the Rust API as closely as possible. If you know acorn-lib, you know acorn-py.
Validate DOIs
🦀 Rust
#![allow(unused)]
fn main() {
use acorn::schema::validate::DOI;
assert!("10.11578/dc.20250604.1".is_doi());
}🐍 Python
from acorn.schema.validate import is_doi
assert is_doi("10.11578/dc.20250604.1")
Find all DOI values in a string
🦀 Rust
#![allow(unused)]
fn main() {
use acorn::schema::pid::DOI;
let pid = "https://doi.org/10.11578/dc.20250604.1";
let text = format!("The DOI for ACORN is: {pid}");
let values = DOI::find_all(&text);
assert_eq!(values[0].identifier(), "10.11578/dc.20250604.1");
}🐍 Python
from acorn.schema.pid import DOI
pid = "https://doi.org/10.11578/dc.20250604.1"
text = f"The DOI for ACORN is: {pid}"
values = DOI.find_all(text)
assert values[0].identifier == "10.11578/dc.20250604.1"
ACORN in a Browser
Warning
This documentation is a work in progress. Some sections may be incomplete or subject to change.